เผยแพร่ครั้งแรกที่ blog.maqe.com
เมื่อช่วงต้นปีที่แล้ว เว็บไซต์ที่บริษัทดูแลอยู่เกิด user surge ขึ้นเป็นช่วงระยะเวลาสั้นๆ ประมาณ 2 สัปดาห์ ถึงแม้ว่าเหตุการณ์จะจบลงอย่างน่าพอใจ สิ่งที่เกิดขึ้นทำให้ทีมต้องกลับมานั่งคิดขยับขยาย infrastructure ที่มีอยู่พอสมควร
แต่ในระหว่างที่วางแผนการสเกลก็มีคำถามเกิดขึ้น เราจะรู้ได้อย่างไรว่าระบบที่เราสเกลออกด้วยจำนวน web server ที่มากขึ้นและ database server ที่ทรงพลังขึ้นจะรับโหลดได้มากขึ้นเท่าไหร่ และที่สำคัญคือเราจะต้องสเกลขึ้นเท่าไหร่จึงจะพอ?
ในบทความนี้จะไม่พูดถึงการคาดการณ์จำนวนผู้ใช้งานในอนาคต ซึ่งเป็นมุมมองฝั่ง business ที่เราไม่ได้ข้อมูลที่แน่นอนมาทำ load testing ในครั้งนั้น จุดประสงค์ของการ load testing ที่เกิดขึ้นจึงเป็นการวัดจำนวนผู้ใช้งานที่ระบบสามารถรองรับได้ด้วย configration ที่แตกต่างกัน เพื่อให้ทาง business สามารถพิจารณาได้ว่ามันเพียงพอสำหรับเขาไหม มีคำตอบให้ทีมสำหรับการสเกลที่อาจเกิดขึ้นในอนาคต และมีหลักฐานยืนยันว่าระบบสามารถรองรับการใช้งานในระดับที่กล่าวถึงได้จริง
คำนิยาม
คำจำกัดความของ load testing, performance testing, stress testing ฯลฯ นั้นแตกต่างกันไปตามลักษณะการทำงานของแต่ละบริษัท แต่เพื่อความเข้าใจที่ตรงกัน ในบทความนี้จึงขอนิยามไว้ 2 คำคือ performance testing และ load testing ไว้ดังนี้
Performance testing
“… general testing performed to determine how a system performs in terms of responsiveness and stability under a particular workload.”
“… การทดสอบใดๆ ที่วัดการตอบสนองและความเสถียร ภายใต้ปริมาณการใช้งานที่กำหนดไว้”
Load Testing
“… the process of putting demand on a system or device and measuring its response.”
“… การทดสอบระบบด้วยการสร้างปริมาณการใช้งานเข้าไปและวัดการตอบสนองของระบบ”
บางท่านอาจสงสัยว่า อ้าว แล้วสุดท้าย load testing มันต่างจาก performance testing อย่างไร ในที่นี้จะมองว่า performance testing คือบังเหียนใหญ่ที่มี load testing และวิธีทดสอบอื่นๆ อยู่ภายใต้ เช่น
- Soak testing (ระบบสามารถรองรับโหลดเป็นระยะเวลานานๆ ได้ไหม)
- Stress testing (ระบบรองรับโหลดที่มากเกินคาดการณ์ได้สูงสุดเท่าไหร่ก่อนที่ระบบจะล่ม หรือล่มแล้วสามารถกลับมาอยู่ในสภาพพร้อมทำงานใหม่ได้หรือไม่)
- ฯลฯ
ซึ่งทั้งหมดเป็นส่วนหนึ่งของการทำ performance testing
การหาโจทย์สำคัญไม่น้อยไปกว่าการหาคำตอบ
คำนิยามและการทำ performance testing นั้นมีหลายรูปแบบ และการทดสอบแต่ละรูปแบบก็จะให้คำตอบที่แตกต่างกัน เพราะฉะนั้นเป็นเรื่องจำเป็นมากที่ต้องตั้งคำถามว่าจะทดสอบไปเพื่ออะไร? โดยในการทดสอบของเราครั้งนี้ก็เพื่อตอบ 3 คำถามนั่นคือ
- ณ ปัจจุบัน ควรใช้ web server และ database server ด้วยจำนวนและขนาดเท่าไหร่?
- สเกลอย่างไรโดยใช้ทรัพยากรให้คุ้มค่ามากที่สุด ไม่เกิดปัญหาคอขวด (เช่นอัพ web server แต่ database ทำงานไม่ทัน ซึ่งจะทำให้การสเกลไม่สมบูรณ์และไม่เกิดประโยชน์)?
- การสเกลขึ้นในแต่ละระดับ จะสามารถรองรับผู้ใช้งานได้มากขึ้นเท่าไร?
คำถามทั้งสามถูกตั้งขึ้นเพราะจุดมุ่งหมายของเราคือ “คนเข้าเยอะขึ้น ระบบต้องไม่ล่ม” หากเราต้องสเกลขึ้นในระยะอันใกล้ถึงปานกลาง เราสามารถตัดสินใจได้ทันทีด้วยตัวเลขที่ได้จากการทดสอบครั้งนี้
ซึ่งหากโจทย์เราไม่ชัดเจน หรือไม่ตรงประเด็น คำตอบที่ได้ก็จะไม่มีประโยชน์ จะเห็นว่าเราไม่ได้ตั้งจุดประสงค์ด้าน response time เลย เพราะเราขอแค่ response time ให้อยู่ในเกณฑ์เดิมก็เพียงพอ
เครื่องมือที่ใช้
เนื่องจากข้อจำกัดทางด้านเวลา เราจึงใช้ Apache JMeter เป็นเครื่องมือในการทดสอบ เพราะเคยใช้มาก่อนแล้วจึงไม่มี learning curve มากนัก
Apache JMeter ขนานนามตัวเองว่า “a 100% pure Java application designed to load test functional behavior and measure performance” ซึ่งถึงแม้ว่าจะเป็น 100% Java แต่ก็สามารถใช้ในโปรเจกต์ที่ใช้ภาษาอื่นๆ ได้ ที่เคยใช้มาก็มีทั้งการทดสอบกับ database server โดยตรง (ผ่าน JDBC) หรือยิงเข้า HTTP service SOAP service ฯลฯ ก็ได้

ออกแบบวิธีการทดสอบ
คำถามที่สำคัญที่สุดของเราคือ จะทำอย่างไรให้มั่นใจว่าการทดสอบนั้นใกล้เคียงการใช้งานจริงมากที่สุด? เช่นหากเรายิงแต่หน้าแรกในขณะที่ผู้ใช้ส่วนใหญ่เข้าไปใช้หน้าอื่นๆ ซึ่งอาจจะกินโหลดเยอะกว่าหรือน้อยกว่าก็ได้ เราจึงใช้แนวทางนี้ในการออกแบบวิธีการทดสอบ
- ดึงข้อมูลการใช้งานเว็บไซต์ออกมาจาก Google Analytics
- สร้าง test cases ที่เทียบเท่าใน Apache JMeter ทั้งในแง่ของ active users, pageviews และหน้าที่ผู้ใช้เข้าถึง
- ทดสอบยิงโหลดเท่ากับจำนวนที่ได้จาก Google Analytics แล้วเทียบกับ New Relic และ Amazon CloudWatch ว่า CPU load / memory usage ที่คล้ายคลึงกับ production environment หรือไม่
นอกจากนี้ ความรีบเร่งของเราทำให้เกิดความ “ลูกทุ่ง” ในการทดสอบหลายอย่าง เช่น
- ใช้เน็ตของบริษัทในการทดสอบ ซึ่งเป็นสายไฟเบอร์เหมือนบริษัททั่วไป
- ยิงทดสอบออกจาก iMac เครื่องเดียว
- ระบบที่ถูกทดสอบตั้งอยู่ที่ประเทศไอร์แลนด์
- ฝั่ง business ไม่ได้ตั้ง expected load มา
เราจึง “แก้เกม” ดังนี้
- เปิด activity monitor และใช้ speed test เพื่อเช็คความเร็ว download/upload สูงสุดของอินเตอร์เน็ต (ทดสอบทั้ง server ไทยและยุโรป)
- เปิด activity monitor เพื่อเช็คว่าไม่มีคอขวดทาง CPU/memory/disk ระหว่างทดสอบ
- เช็คด้วย New Relic APM ว่า requests per minute เพิ่มขึ้นตามแผนทดสอบ
- ยิงโหลดไปยังไฟล์ robots.txt เพื่อเช็ค response time แล้วใช้ค่านี้เป็น baseline
- ในเมื่อไม่มี expected load มาให้ เราจึงตั้ง configurations ในการสเกลหลายๆ แบบ และลองทดสอบไปทีละ configuration และสรุปผลออกเป็นตาราง
และนี่คือหน้าตาของ Test Plan ที่ถูกสร้างขึ้นใน Apache JMeter
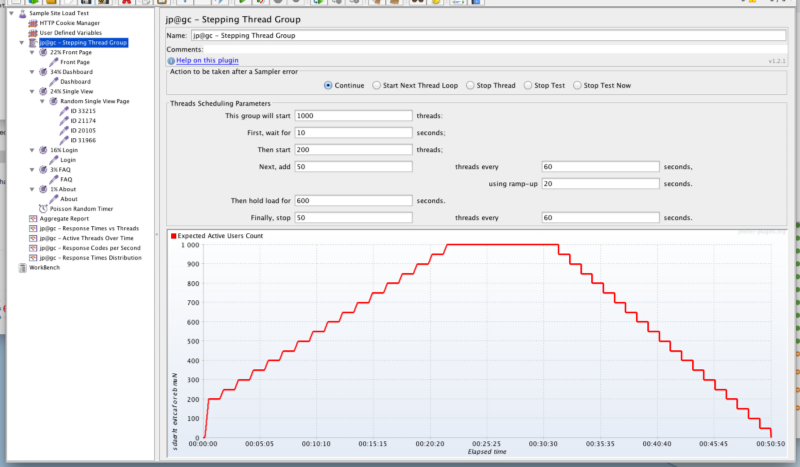
หน้าตา Test Plan ที่ถูกสร้างขึ้นใน Apache JMeter
นอกจากตัวโปรแกรม Apache JMeter แล้ว ในรูปด้านบนเราเพิ่ม jmeter plugins (http://jmeter-plugins.org/) เพื่อเพิ่มฟีเจอร์ที่ช่วยอำนวยความสะดวกในการทำการทดสอบด้วยดังนี้
- jp@gc — Stepping Thread Group: สำหรับใส่จำนวนผู้ใช้จำลอง ตั้งแต่จุดที่เริ่มต้นทดสอบและเพิ่ม/ลดจำนวน thread ตามระยะเวลาได้อย่างสะดวก
- jp@gc — Response Time vs Threads: เป็นหน้าหลักที่เราใช้ตรวจสอบการตอบสนองของระบบ เราสามารถเช็คได้ว่าระบบเริ่มรองรับไม่ไหวจากกราฟ Response Time ที่เริ่มทะยานขึ้นได้
- jp@gc — Active Threads Over Time: สำหรับเช็คจำนวนผู้ใช้ที่เราจำลองขึ้น ณ จุดใดจุดหนึ่งของการทดสอบ
- jp@gc — Response Codes per Second: สำหรับตรวจสอบว่าระบบยังตอบสนองกลับมาเป็น 200 OK อยู่ ไม่ใช่ว่า response กลับมาเร็วแต่เป็น 500 Internal Server Error ฯลฯ
- jp@gc — Response Times Distribution: แสดง distribution graph ให้เห็นว่าการกระจายตัวของ response time จำแนกตามหน้าที่ยิง
ผลลัพธ์
ขออนุญาตแสดงเป็น screen capture ของแง่มุมต่างๆ ที่เราสามารถสรุปได้จากข้อมูลที่ได้มา
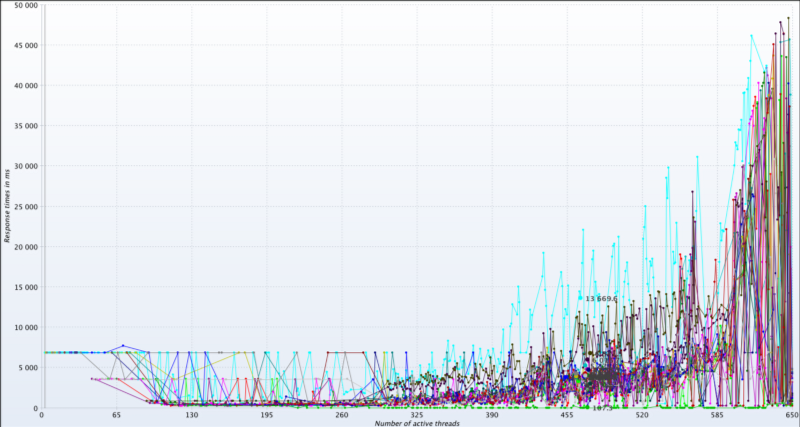
ด้านล่างเป็นกราฟ response time vs active threads แสดงให้เห็นว่าระบบตอบสนองได้เสถียรดีไปตลอดจนถึง 400 threads กราฟสีฟ้าๆ คาดว่าเป็นปัญหาภายในเน็ตเวิร์คของบริษัทเอง ส่วนค่าแกน Y ที่สูงอย่าไปสนใจมันมากครับ เทสระบบอ้อมไปครึ่งโลก แถมทดสอบครั้งนี้ก่อนหน้าที่จะทำ optimization ด้วย
กราฟ response time vs active threads
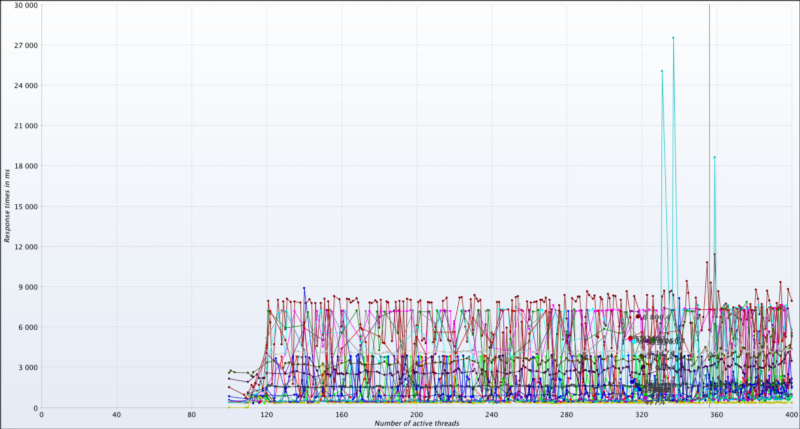
เมื่อเห็นว่าระบบยังตอบสนองได้ดีจนถึง 400 active threads เราก็จัดการทดสอบอีกครั้งโดยเพิ่ม max. active threads ให้สูงขึ้นไปอีก กราฟด้านล่างแสดงให้เห็นชัดเจนว่าด้วย configuration นี้ ระบบเริ่มไม่เสถียรตั้งแต่ 400 threads เป็นต้นไป และแสดงให้เห็นด้วยว่า endpoint สีฟ้า ถึงแม้ response time จะสูสีกับคนอื่นมาตลอด กลายเป็นตัวแรกที่แสดงอาการเมื่อโหลดสูงขึ้น
ในบางครั้ง เมื่อเราเร่ง active threads ขึ้นไปเยอะมากๆ อยู่ดีๆ response time ก็ตกลงไปอย่างน่าแปลกใจ แต่เมื่อมาดูที่กราฟ response codes per second ก็ทำให้พบว่า response time ไม่ได้แปลว่าระบบทำงานได้ดีขึ้นที่จำนวน threads เยอะๆ แต่มันเริ่มพ่น error กลับมาแล้วต่างหาก จากนั้นเราสามารถย้อนกลับไปดูที่กราฟ active threads over time ได้ว่า ณ เวลานั้นมี active threads เท่าไร
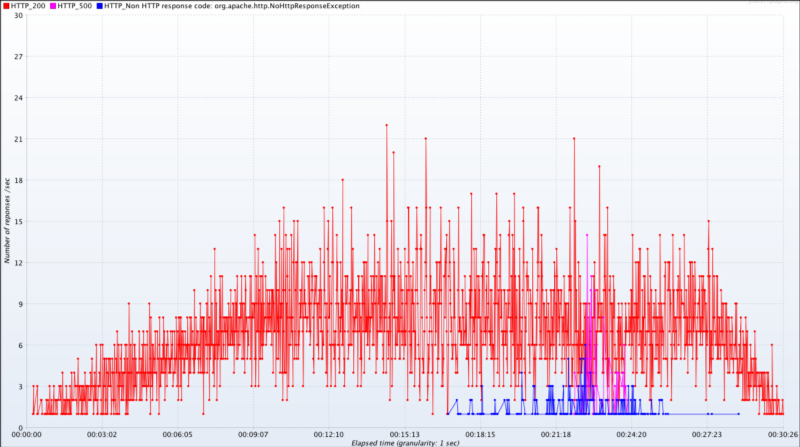
กราฟ response codes per second ทำให้เรารู้ว่า response time ที่แลดูนิ่งๆ ช่วงนาทีที่ 17 เป็นต้นไปไม่ใช่เพราะระบบทำงานดีขึ้น แต่เป็นเพราะมันเริ่มล่มแล้วต่างหาก
เมื่อเราทดสอบซ้ำๆ กับหลายๆ combination ทำให้เราสามารถสรุปผลออกมาเป็นตาราง ซึ่งตอบคำถามตั้งต้นของเราได้
- ณ ปัจจุบัน ควรใช้ web server และ database server ด้วยจำนวนและขนาดเท่าไหร่?
- สเกลอย่างไรโดยใช้ทรัพยากรให้คุ้มค่ามากที่สุด ไม่เกิดปัญหาคอขวด (เช่นอัพ web server แต่ database ทำงานไม่ทัน ซึ่งจะทำให้การสเกลไม่สมบูรณ์และไม่เกิดประโยชน์)?
- การสเกลขึ้นในแต่ละระดับ จะสามารถรองรับผู้ใช้งานได้มากขึ้นเท่าไร?
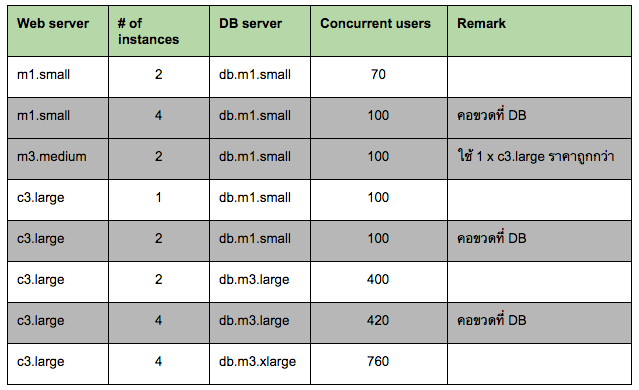
ผลลัพธ์ (แถม)
เนื่องจากระบบที่ทดสอบมี New Relic APM (Application Performance Monitoring), New Relic Servers (Server Monitoring) และ Amazon CloudWatch อยู่แล้ว เราจึงใช้อย่างเต็มที่เพื่อเก็บข้อมูลอื่นๆ ซึ่งทำให้เราเข้าใจระบบของเรามากขึ้นไปอีก
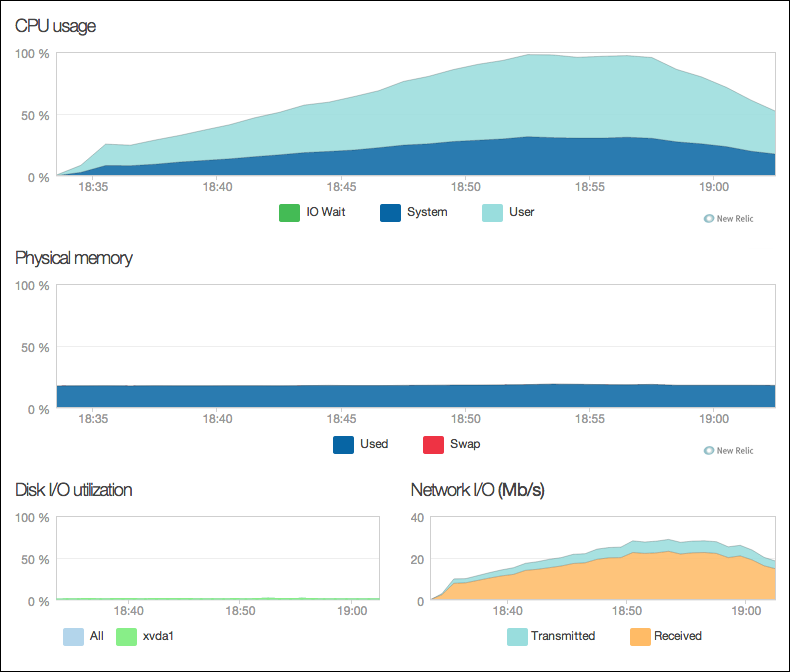
New Relic ช่วยให้เราสามารถสังเกตการณ์โหลดฝั่ง web server ไปพร้อมๆ กันระหว่างการทดสอบ ทำให้เราเห็นการทำงานของระบบมากขึ้น (ใช้ AWS Cloudwatch ฯลฯ แทนก็ได้นะ)
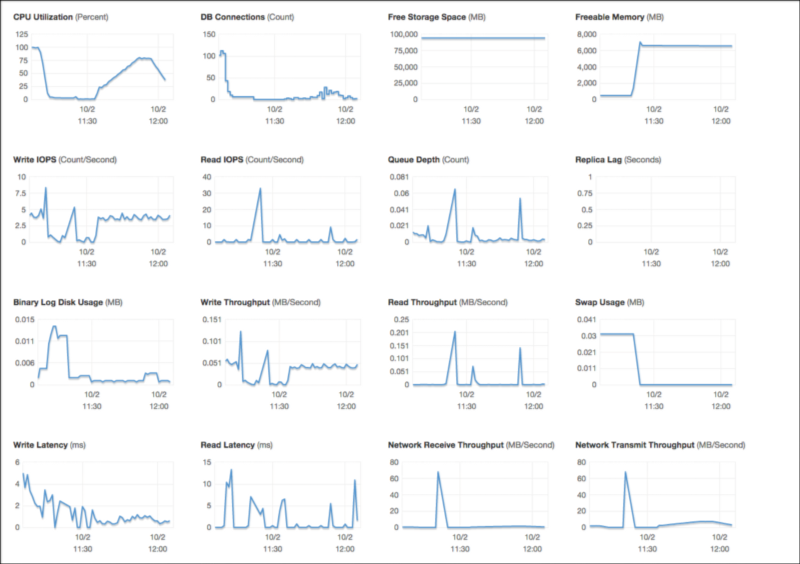
หน้าตาของ Amazon CloudWatch ฝั่ง Database ทำให้เราสังเกตการณ์โหลดบนฐานข้อมูลได้เช่นกัน
Load testing ก่อนและหลังทำ code optimization
หลังจากที่ได้ผลลัพธ์ข้างต้น เราได้หยิบ 2 endpoints มาทำ code optimization เพื่อให้โค๊ดใช้ทรัพยากรระบบลดลง ปรากฎว่าการเปรียบเทียบผลลัพธ์ระหว่างก่อนและหลังการทำ optimization ยิ่งมีความน่าสนใจเข้าไปอีก เพราะนอกจากมันจะทำให้ endpoint ทั้งสองประมวลผลเร็วขึ้นแล้ว ยังทำให้ระบบโดยรวมมี response time เร็วขึ้นสูงสุดกว่า 5 เท่า แต่ความเสถียรกลับผันผวนมากขึ้นตั้งแต่ 320 threads ขึ้นไป (ยังเร็วกว่าก่อน optimization อยู่ดี)
ซึ่งแสดงให้เห็นว่าการทำ load testing เป็นระยะๆ จะทำให้เราเห็นและทำความเข้าใจพฤติกรรมของระบบได้ดีขึ้น
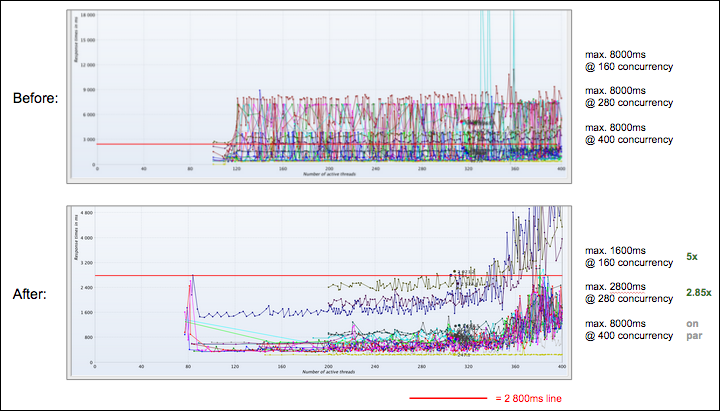
เราทำ code optimization ไปเพียง 2 endpoints แต่ระบบโดยรวมกลับเร็วขึ้นทั้งหมด ถึงแม้ว่า response time เริ่มผันผวนเร็วขึ้นกว่าเดิม
ทิ้งท้าย
นอกจากการทำ load testing ทำให้เรารู้ว่าระบบของเราสามารถรองรับผู้ใช้ได้มากเท่าไรแล้ว ยังทำให้เราเข้าใจพฤติกรรมของระบบมากขึ้น เช่นความสัมพันธ์ระหว่างโหลดของ web server และ DB server หรือแม้กระทั่งใช้เป็นข้อมูลเบื้องต้นในการทำ code optimization ต่อไป
อย่างไรก็ตาม การทดสอบที่เกิดขึ้นด้านบนนี้ก็อยู่บนพื้นฐานของความ “ลูกทุ่ง” อยู่มาก เพื่อแลกมากับความรวดเร็วในการทดสอบ ทั้งนี้เราก็ได้รวบรวมข้อสังเกตเพื่อพัฒนาการทดสอบของเราในโอกาสต่อๆ ไปดังนี้
- ต้องทำ performance testing อย่างสม่ำเสมอ เพราะเราไม่รู้ว่าฟีเจอร์ที่เปลี่ยนแปลงไป จะมีผลกระทบต่อระบบโดยรวมอย่างไร
- เราปิด caching ทิ้งระหว่างการทดสอบ เนื่องจากข้อจำกัดด้านเวลาทำให้ไม่สามารถออกแบบ test plan ที่ซับซ้อนขึ้นได้
- การทำ performance testing ที่ผลลัพธ์เที่ยงตรงมากขึ้นและทดสอบด้วย concurrent users จำนวนมากขึ้น ควรย้ายไปใช้บริการ Cloud Load Testing เช่น Load Impact, Flood.io, Blitz.io ฯลฯ
- ควรจัดหาวิธีการเก็บบันทึกผลลัพธ์อย่างเป็นระบบ เพื่อให้สามารถเปรียบเทียบผลลัพธ์ระหว่างการทดสอบแต่ละครั้งได้
- ยังมีตัวแปรอื่นๆ ที่สำคัญที่เรา ไม่ได้ทดสอบในครั้งนี้ เช่น stress test, soak test ฯลฯ ซึ่งล้วนแล้วจะทำให้ผลการทดสอบเชื่อถือได้มากขึ้น และครอบคลุมการใช้งานจริงของระบบมากขึ้น
หากท่านใดมีความคิดเห็นอื่นๆ เกี่ยวกับการทดสอบครั้งนี้ เรายินดีรับคำแนะนำและปรับปรุงบทความเพื่อให้เป็นประโยชน์ต่อสาธารณะมากขึ้นครับ